![]()
About
The EpiSewer R package provides a Bayesian generative model to estimate the effective reproduction number Rt and other transmission indicators from pathogen concentrations measured in wastewater. This enables tracking of transmission dynamics both retrospectively and in real time. EpiSewer is tailored to the specifics of wastewater concentration measurements, offers comprehensive uncertainty quantification via MCMC sampling in stan, and provides easily configurable modeling components. See our paper for a detailed assessment of the model’s performance.
Model highlights
Measurements
⭐ Non-daily / missing measurements
⭐ Multiple measurements (replicates) per sample
⭐ Multi-day composite samples
⭐ Accurate dPCR noise model
⭐ Limit of detection (LOD) model
Sampling
⭐ Integrated outlier detection
⭐ Sample batch effects (e.g. weekday or age-of-sample effects)
Sewer
⭐ Flow normalization
⭐ Sewer residence time distributions
Shedding
⭐ Shedding load distributions (with uncertainty)
⭐ Individual-level shedding load variation
Infections
⭐ Stochastic infection model with overdispersion
⭐ Flexible smoothing (Gaussian process, random walk, exponential smoothing, splines, changepoint models)
⭐ Transmission indicators: , growth rate, doubling time, and more
Forecast
⭐ Probabilistic forecasts of , infections, concentrations and more
Installing the package
The development version of EpiSewer can be installed from GitHub as shown below. Please note that the package is still in early development and may be subject to breaking changes.
remotes::install_github("adrian-lison/EpiSewer", dependencies = TRUE)EpiSewer requires a Stan sampling backend. There are two options:
- 🔧 Install CmdStan locally: See the cmdstan installation vignette for step-by-step instructions.
- 🐳 Use a Docker container: If you cannot install CmdStan on your system, you can run EpiSewer inside a pre-built Docker image. See the docker vignette for instructions.
Snakemake workflow 🐍
EpiSewer can also be used with pipeline orchestration software - see here for a Snakemake workflow example.
Introduction
You have installed EpiSewer and the stan backend, and are ready to analyze your wastewater data? Then follow the quick introduction below to learn how to use the package. For more details on how to customize the model, see the model specification and detailed example vignettes on the package website.
Data
Data requirements
The below example of wastewater data is from Zurich, Switzerland. Data are provided by EAWAG (Swiss Federal Institute of Aquatic Science and Technology) to the public domain (CC BY 4.0 license).
data_zurich <- SARS_CoV_2_Zurich
names(data_zurich)
#> [1] "measurements" "flows" "cases" "units"-
measurements:EpiSewerrequires a time series of concentration measurements. Measurements should ideally be in gc/mL (gc = gene copies). -
flows: Data about the daily wastewater volume flowing through the sampling site (should be in mL/day). Flow data is highly recommended, but not strictly necessary (see documentation offlows_assume()). -
cases: Data about confirmed cases in the catchment area. This is optional but can help informing some of our prior assumptions.
Measurements
The measurements data contains daily viral concentration measurements (in gc/mL) for the SARS-CoV-2 N1 gene at the wastewater treatment plant in Zurich. Some days have missing measurements, but this is no problem: EpiSewer naturally accounts for missing values during estimation.
data_zurich$measurements
#> date concentration
#> <Date> <num>
#> 1: 2022-01-01 NA
#> 2: 2022-01-02 NA
#> 3: 2022-01-03 455.7580
#> 4: 2022-01-04 747.8792
#> 5: 2022-01-05 573.7020
#> ---
#> 116: 2022-04-26 182.3664
#> 117: 2022-04-27 379.2421
#> 118: 2022-04-28 439.7427
#> 119: 2022-04-29 394.0033
#> 120: 2022-04-30 293.1242To show the handling of missing data more clearly, we make our data artificially sparse by keeping only measurements that were made on Mondays and Thursdays. This means we will only have two measurements per week.
measurements_sparse <- data_zurich$measurements[,weekday := weekdays(data_zurich$measurements$date)][weekday %in% c("Monday","Thursday"),]
head(measurements_sparse, 10)
#> date concentration weekday
#> <Date> <num> <char>
#> 1: 2022-01-03 455.7580 Monday
#> 2: 2022-01-06 330.7298 Thursday
#> 3: 2022-01-10 387.6885 Monday
#> 4: 2022-01-13 791.1111 Thursday
#> 5: 2022-01-17 551.7701 Monday
#> 6: 2022-01-20 643.9910 Thursday
#> 7: 2022-01-24 741.9150 Monday
#> 8: 2022-01-27 770.1810 Thursday
#> 9: 2022-01-31 627.1725 Monday
#> 10: 2022-02-03 561.2913 ThursdayFlows
The flows data tracks the daily flow (in mL/day) at the treatment plant in Zurich. The flow data will be used to normalize the concentration measurements. This helps to account for environmental factors such as rainfall. It is important that the flow uses the same volume unit as the concentration (mL here in both cases).
data_zurich$flows
#> date flow
#> <Date> <num>
#> 1: 2022-01-01 3.41163e+11
#> 2: 2022-01-02 3.41163e+11
#> 3: 2022-01-03 1.58972e+11
#> 4: 2022-01-04 1.60849e+11
#> 5: 2022-01-05 3.72301e+11
#> ---
#> 116: 2022-04-26 3.30659e+11
#> 117: 2022-04-27 2.06046e+11
#> 118: 2022-04-28 1.58373e+11
#> 119: 2022-04-29 1.52156e+11
#> 120: 2022-04-30 2.08685e+11❗ Note: It’s not a problem if you only have flow data on dates with measurements. However, for each measured date, there must also be a flow value. If flow information is missing for measured dates, please make sure to impute it using a suitable method before passing it to EpiSewer (or drop those dates).
Cases
Finally, if we have case data available, we can also pass this to EpiSewer. This is then used to calibrate the model so that the estimated number of infections approximately matches the observed number of cases.
data_zurich$cases
#> date cases
#> <Date> <num>
#> 1: 2022-01-01 NA
#> 2: 2022-01-02 NA
#> 3: 2022-01-03 1519.5313
#> 4: 2022-01-04 1727.3722
#> 5: 2022-01-05 1638.5321
#> ---
#> 116: 2022-04-26 211.9338
#> 117: 2022-04-27 214.9822
#> 118: 2022-04-28 206.2498
#> 119: 2022-04-29 151.9567
#> 120: 2022-04-30 134.8545If you don’t have case data: don’t worry! In general, the assumed shedding load per case does not have a large effect on the effective reproduction number, and EpiSewer will use a robust default. You just have to keep in mind that the absolute number of infections estimated by EpiSewer should not be interpreted as true incidence or prevalence.
Gather the data
We combine the measurements data and flow data using the helper function sewer_data(). We here use our artificially sparse measurements (only Mondays and Thursdays). For calibration purposes, we also supply the case data, as explained above.
ww_data <- sewer_data(
measurements = measurements_sparse,
flows = data_zurich$flows,
cases = data_zurich$cases # cases are optional
)Assumptions
In order to estimate the effective reproduction number from wastewater concentration measurements, we have to make a number of assumptions.
- Generation time distribution: Distribution of the time between a primary infection and its resulting secondary infections
- Shedding load distribution: Distribution of the load shed by an average individual over time. We also specify that our distribution is relative to the day of symptom onset.
- Incubation period distribution: Because our shedding load distribution is in days since symptom onset, we also need to make an assumption about the time between infection and symptom onset.
The generation time, shedding load and incubation period distribution are all disease-specific and are typically obtained from literature. EpiSewer requires these distributions to be discretized, and offers specific functions to obtain discretized versions of popular continuous probability distributions.
ww_assumptions <- sewer_assumptions(
generation_dist = get_discrete_gamma_shifted(gamma_mean = 3, gamma_sd = 2.4),
shedding_dist = get_discrete_gamma(gamma_shape = 0.929639, gamma_scale = 7.241397),
shedding_reference = "symptom_onset", # shedding load distribution is relative to symptom onset
incubation_dist = get_discrete_gamma(gamma_shape = 8.5, gamma_scale = 0.4)
)💡 Sometimes, shedding load distributions are instead specified in days since infection. In that case, you can use shedding_reference = "infection" and don’t need to supply an incubation period distribution.
Estimation
Now that we have the data and necessary assumptions, we can use EpiSewer to estimate the effective reproduction number. We here use the default model and settings provided by EpiSewer. With the helper function set_fit_opts() we specify our sampling approach: we apply Hamiltonian MCMC sampling via stan, using 4 chains with 500 warmup and 500 sampling iterations each.
Stan regularly provides updates about the sampling process. The overall runtime will depend on your hardware resources, the size of the data, the complexity of the model used, and how well the model actually fits the data. On a modern laptop the example below should take about 3 minutes to run.
options(mc.cores = 4) # allow stan to use 4 cores, i.e. one for each chain
ww_result <- EpiSewer(
data = ww_data,
assumptions = ww_assumptions,
fit_opts = set_fit_opts(sampler = sampler_stan_mcmc(
iter_warmup = 500, iter_sampling = 500, chains = 4, seed = 42
))
)💡 We are here using a shorthand version of the EpiSewer() function which uses all available default settings. To find out how the EpiSewer model can be customized, see the model specification and detailed example vignettes.
Plotting the results
Great, the sampling has completed! Now we can inspect the results of our model. Plots are a convenient way to get a quick overview.
Model fit
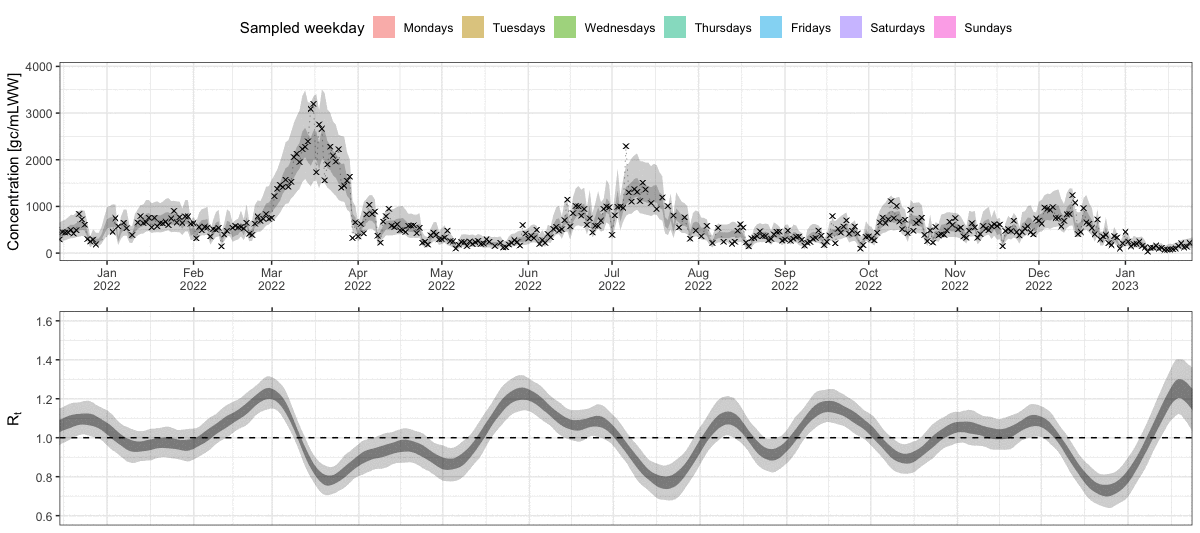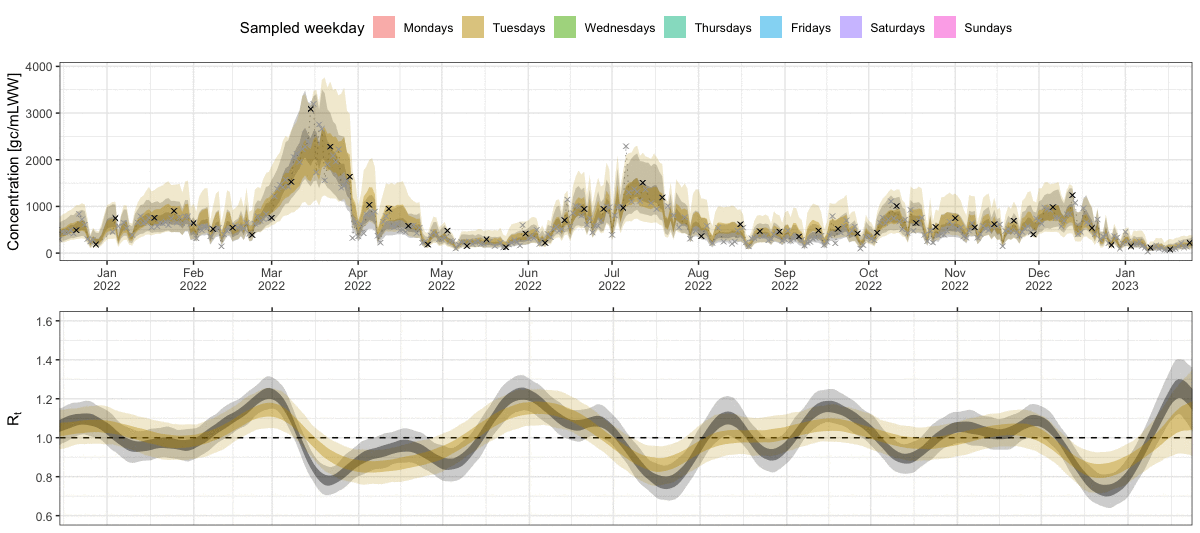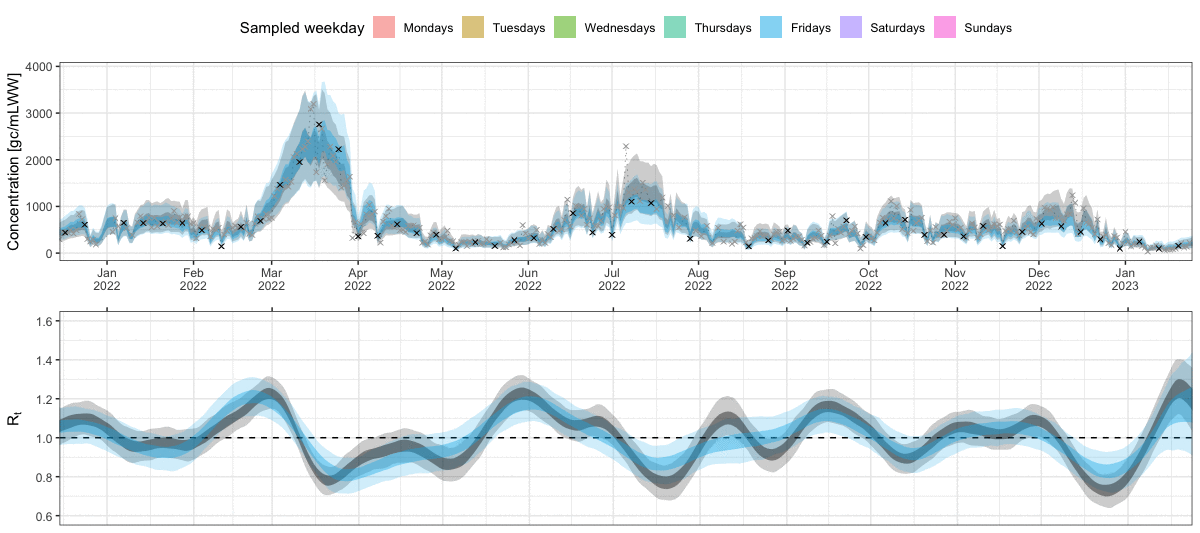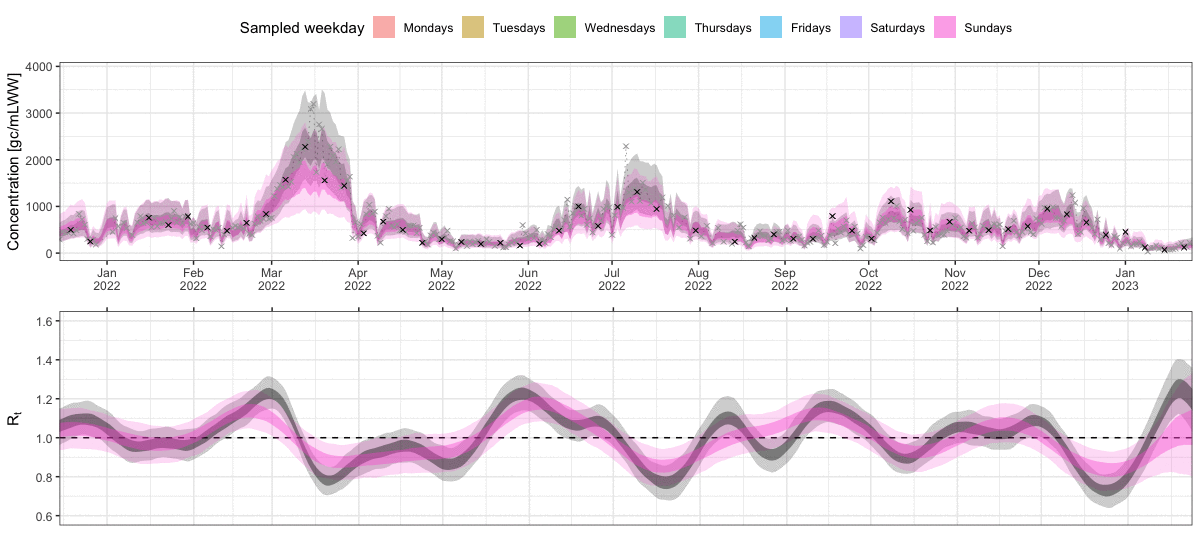
It is good practice to first assess how well the model actually fitted to the data. For this, we plot the observed concentration measurements against the ones predicted by the model. The inner and outer ribbons show the 50% and 95% credible intervals. The black dots show measurements that we have actually observed in our artificially sparse data set (only Mondays and Thursdays). The grey crosses show all the other measurements that were not available to the model. As we can see, the model still achieved a decent fit on these missing days.
plot_concentration(ww_result, measurements = data_zurich$measurements)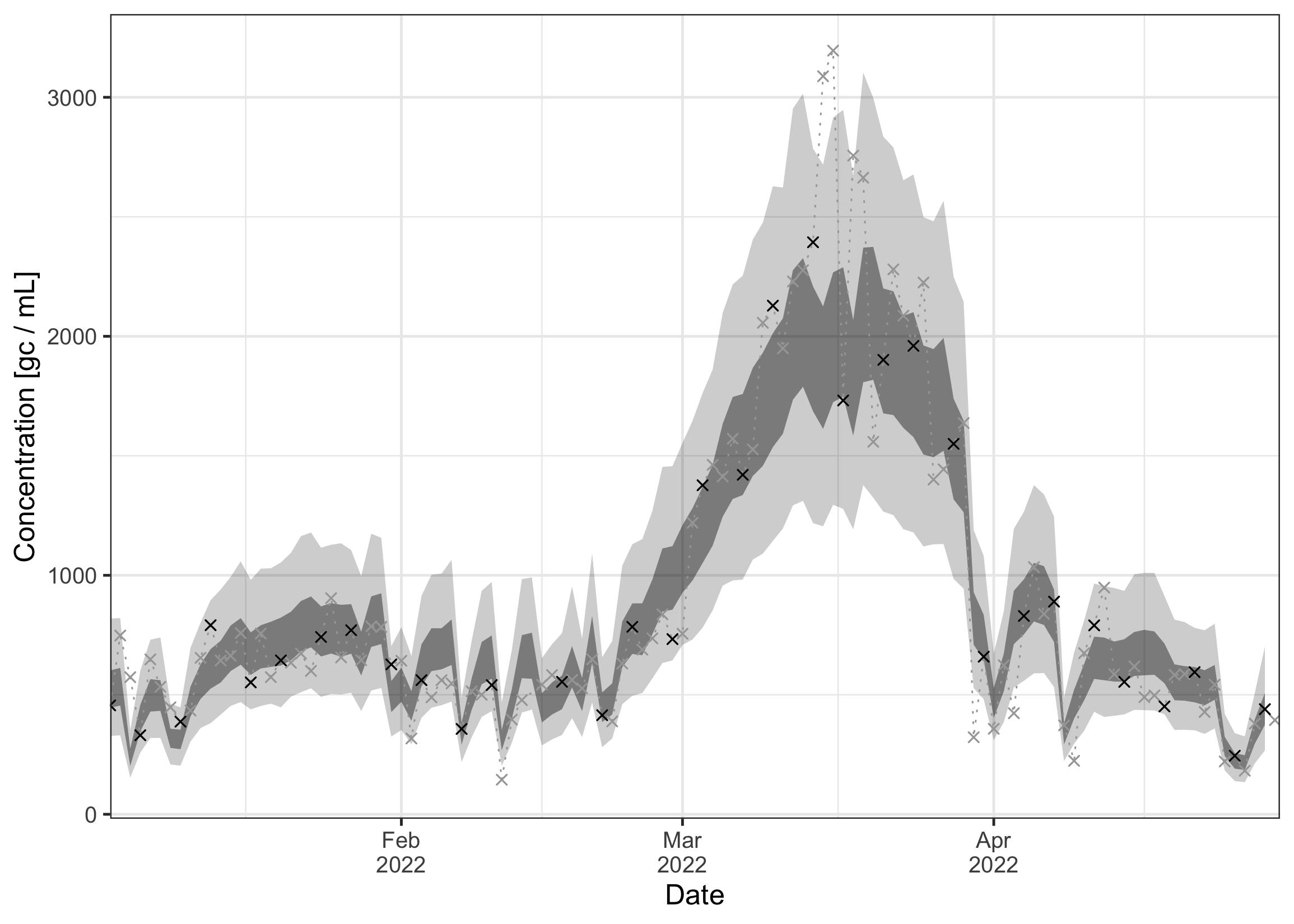
By default, the function plot_concentration() shows absolute concentrations, which strongly depend on the daily wastewater flow. Alternatively, we can plot the flow-normalized concentration by setting normalized = TRUE. This will show the hypothetical concentration if the flow was at its median value. For this option, we need to provide the flow data as well (see below).
plot_concentration(ww_result, measurements = data_zurich$measurements, flows = data_zurich$flows, normalized = TRUE)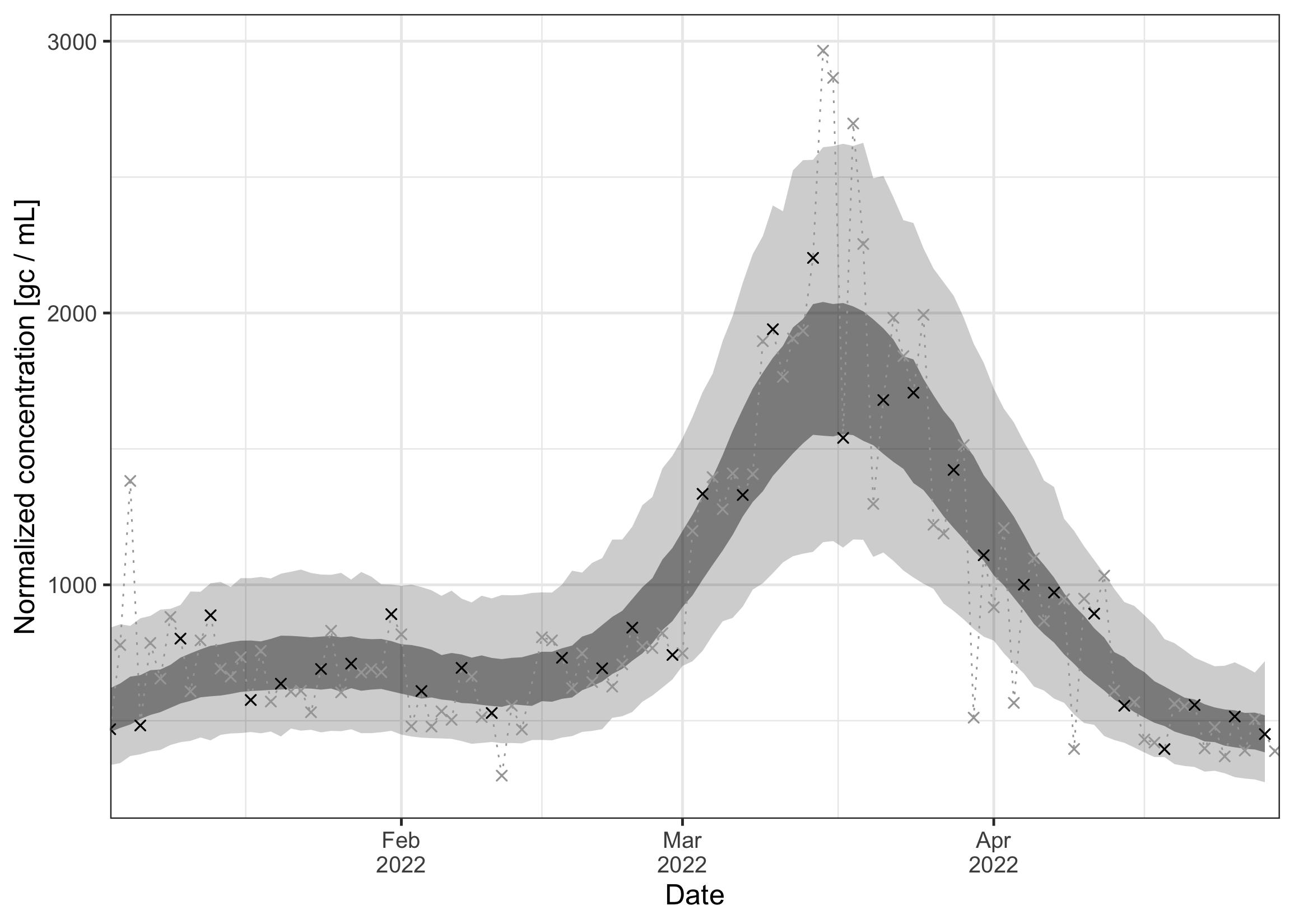 As can be seen, the normalization removes the noise due to the daily variation of flow. The remaining uncertainty is due to the measurement noise and other sources of variation.
As can be seen, the normalization removes the noise due to the daily variation of flow. The remaining uncertainty is due to the measurement noise and other sources of variation.
Time-varying effective reproduction number
Since the model fit looked decent at first glance, we now inspect our main parameter of interest, the effective reproduction number over time. Again, the ribbons show the 50% and 95% credible intervals. We see that even with only two measurements per week, we get a fairly clear signal for R being above or below the critical threshold of 1.
plot_R(ww_result)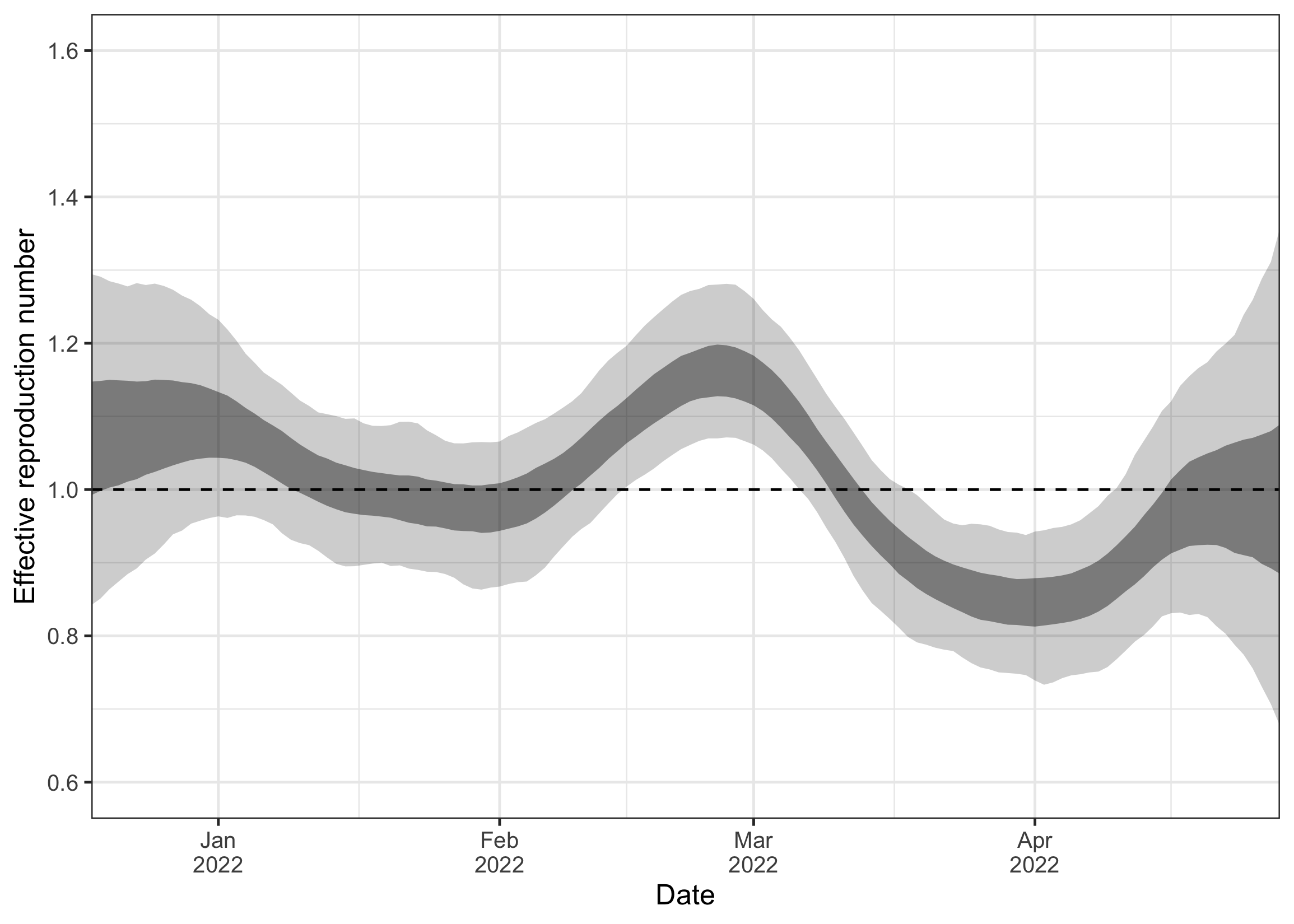
Note that the estimates for R go back further into the past than our observations. This is due to the delay from infection to shedding, i.e. concentration measurements observed today are mostly a signal of infections in the past. This is also why the R estimates close to the present are strongly uncertain. The measurements observed until the present provide only a delayed signal about transmission dynamics, so the most recent R estimates are informed by only little data.
Growth report
We can also display a growth report which shows the probability that infections have been growing for a prolonged period of time. By default, EpiSewer selects the most recent date for which reliable estimates are possible as a reference.
plot_growth_report(ww_result)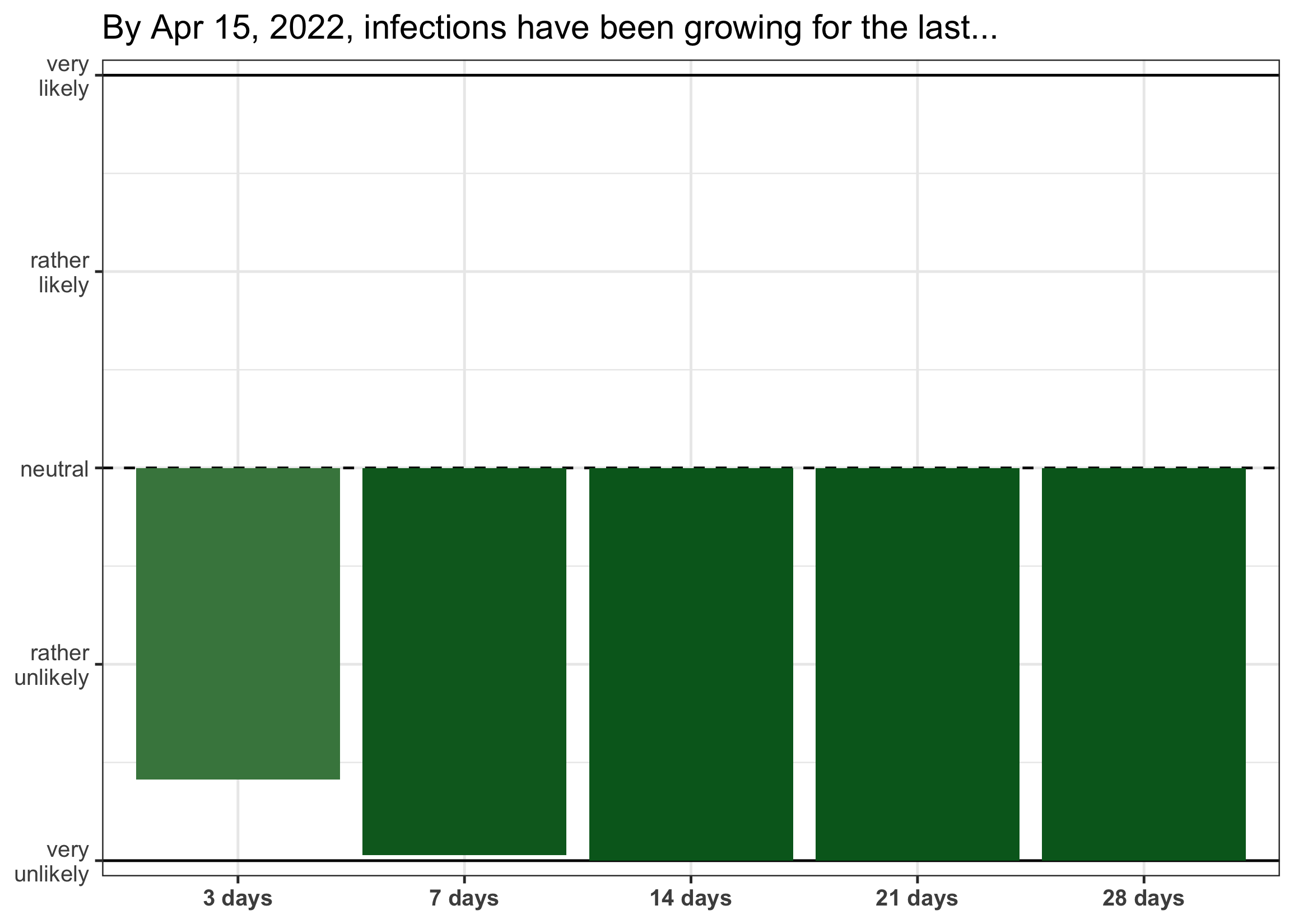 As the model was fitted at the end of the seasonal wave in Zurich, there is high posterior support that infections are currently not growing for a prolonged period of time.
As the model was fitted at the end of the seasonal wave in Zurich, there is high posterior support that infections are currently not growing for a prolonged period of time.
You can also display a growth report for other dates. Let’s for example have a look at the report for mid-February 2022. Here we can see that there is strong posterior support that infections have been growing for at least a week. At the same time, it seems rather unlikely that they have already been growing for 3 weeks or longer.
plot_growth_report(ww_result, date = "2022-02-19")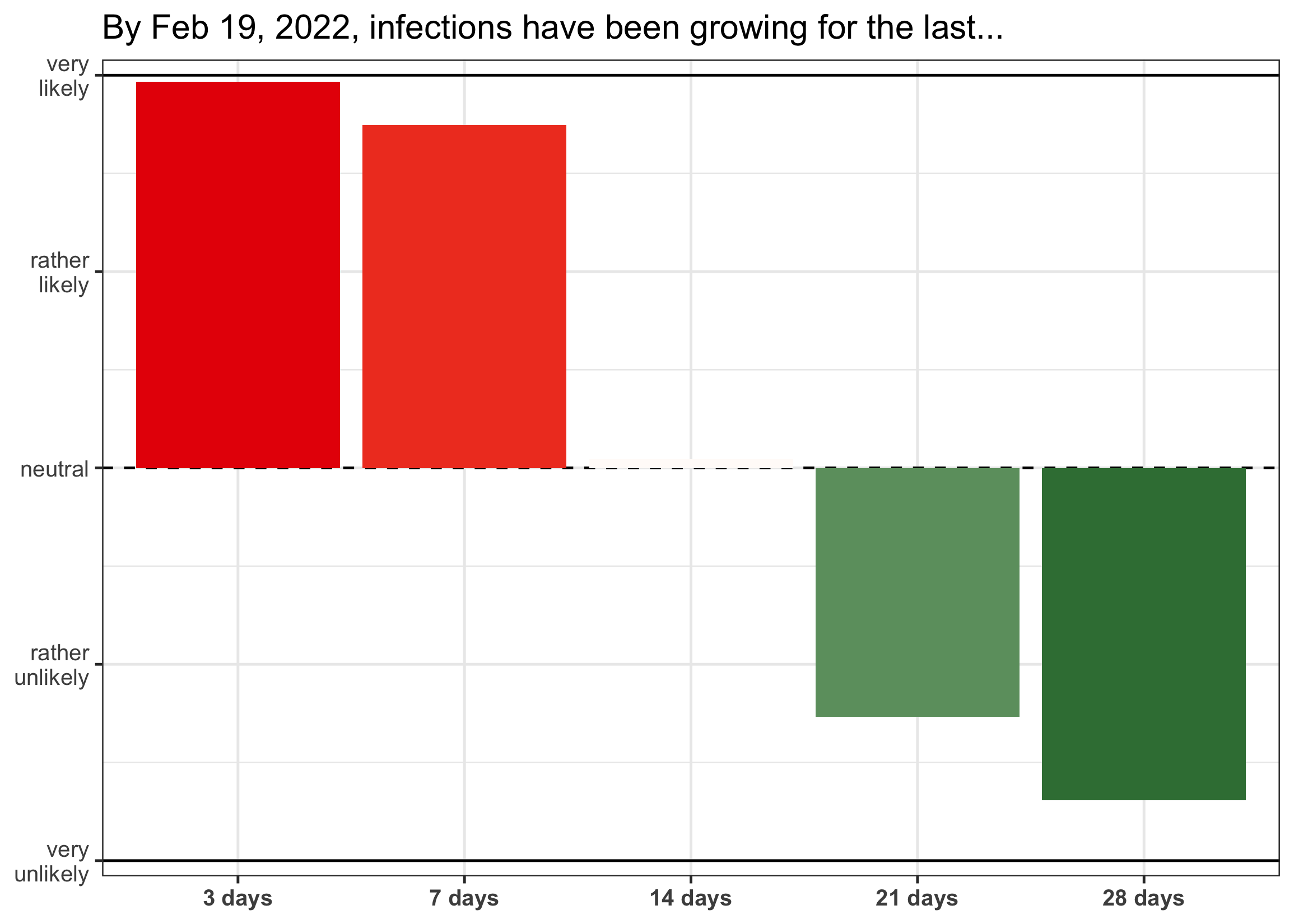
💡 EpiSewer also provides further indicators of transmission dynamics, see e.g. plot_growth_rate() and plot_doubling_time(). These can however be more volatile and sometimes difficult to interpret.
Latent parameters
We can also inspect other internal parameters of the model. This may give us a better understanding of the model fit and may help to diagnose certain problems.
First, we plot the estimated load over time. This is the expected total load that arrived at the sampling side on a given day. We can see this is roughly on the order 1e14 to 3e14.
plot_load(ww_result)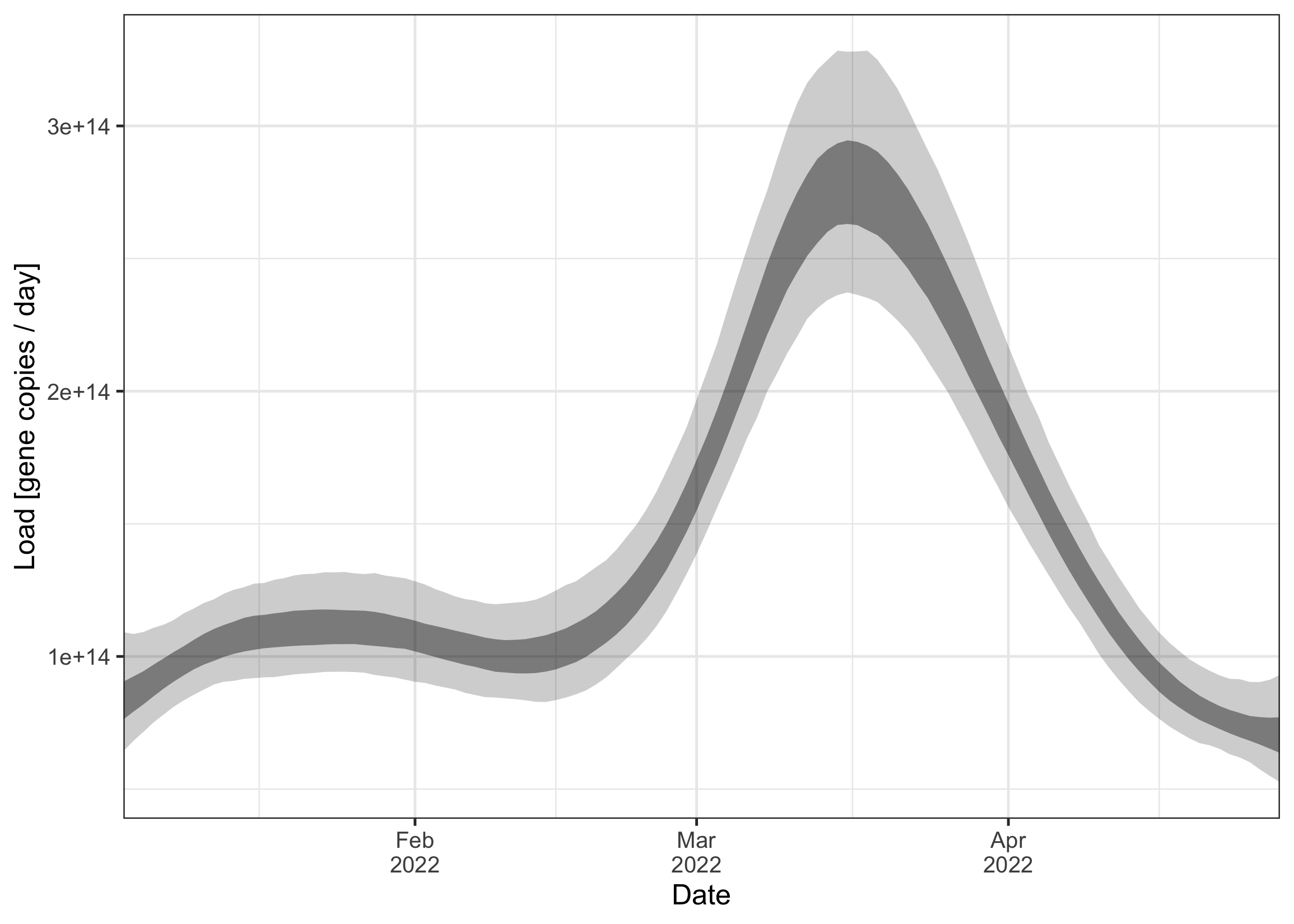 Next, we plot the estimated number of infections over time. The time series follows a very similar trend as the load. Compared to the load, the peak in infections seems to be a bit more spiked, and also a bit earlier. This is because infected individuals only begin shedding after their infection and then shed over a longer period of time (as defined by the incubation period and shedding load distribution). This makes the load a slightly delayed and blurred signal of the infections.
Next, we plot the estimated number of infections over time. The time series follows a very similar trend as the load. Compared to the load, the peak in infections seems to be a bit more spiked, and also a bit earlier. This is because infected individuals only begin shedding after their infection and then shed over a longer period of time (as defined by the incubation period and shedding load distribution). This makes the load a slightly delayed and blurred signal of the infections.
plot_infections(ww_result)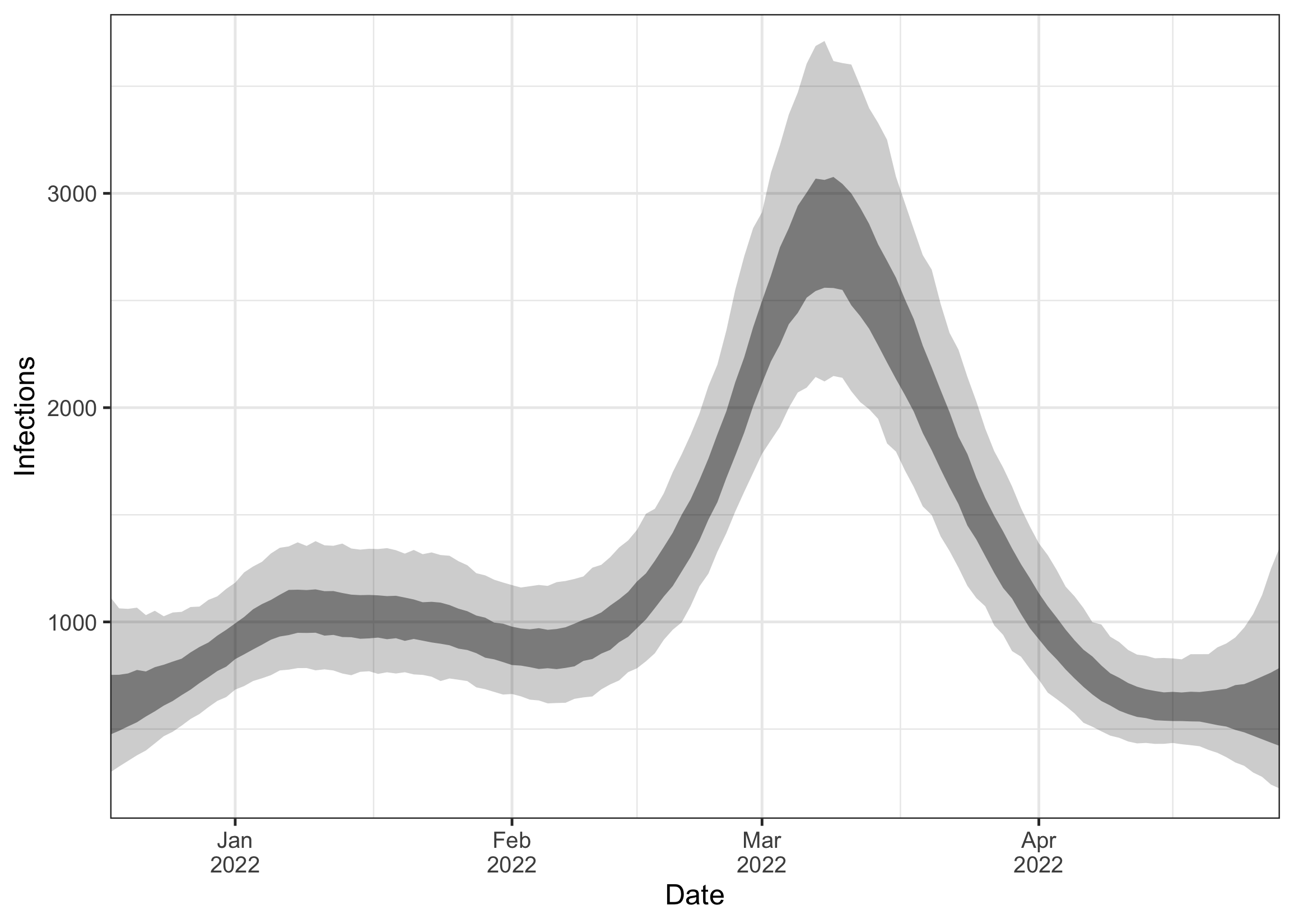
Note that because we supplied case data, the estimated infections rougly match the case numbers (plotted in blue below). Nevertheless, the infections plot shown here should only be used for diagnostic purposes, for example to ensure that the trend looks sensible and that the scale of infections is not unrealistic (not millions of infections or 0.01 infections per day). Please do not interpret the estimated number of infections in terms of true absolute incidence or prevalence.
plot_infections(ww_result) + geom_step(data = data_zurich$cases, aes(x = date, y = cases), color = "#000080")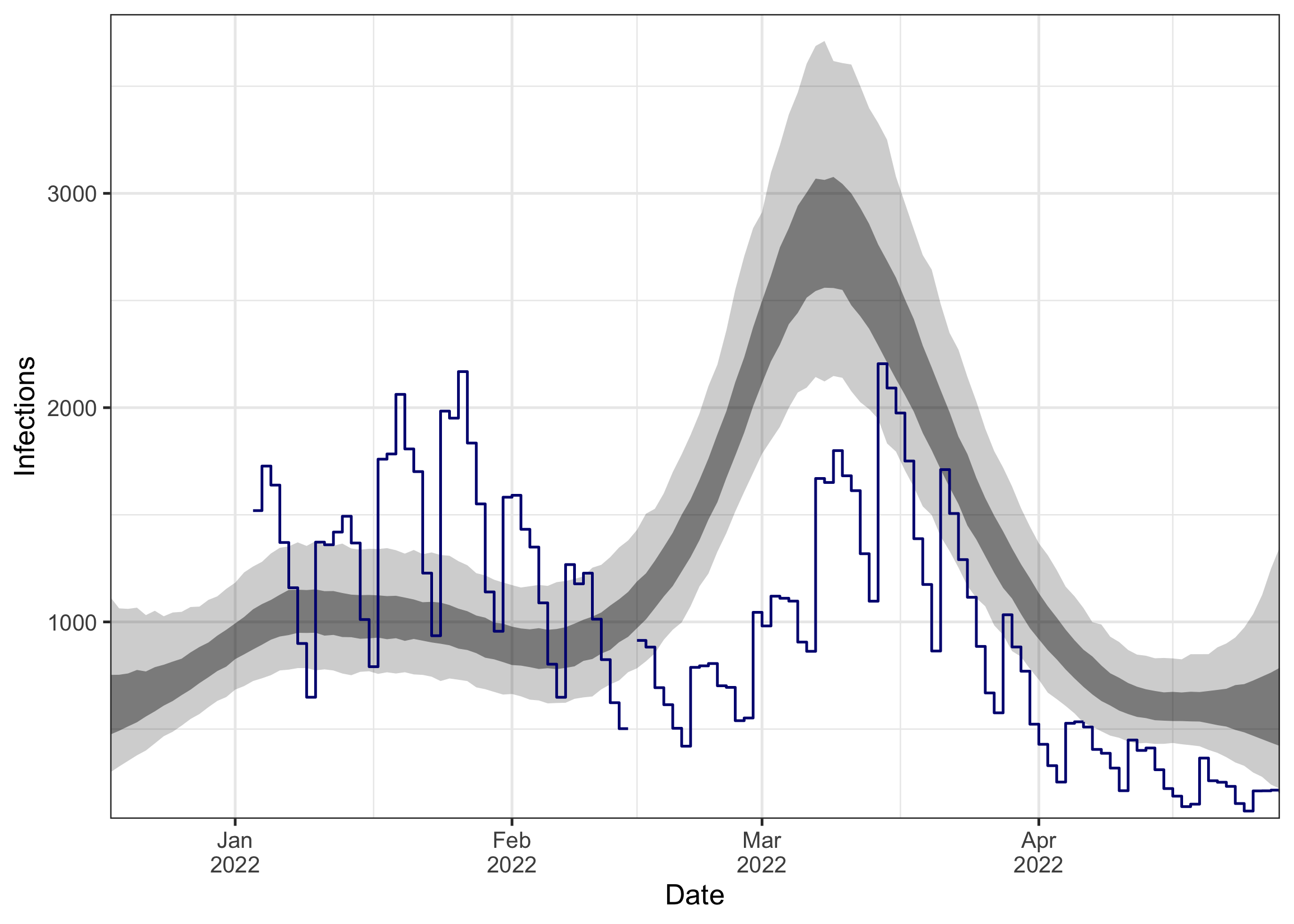
We can also compare the prior and posterior distribution for certain parameters of the model to see how much they were informed by the data. For example, we can inspect the coefficient of variation (CV) of the observation noise:
plot_prior_posterior(ww_result, "measurement_noise_cv")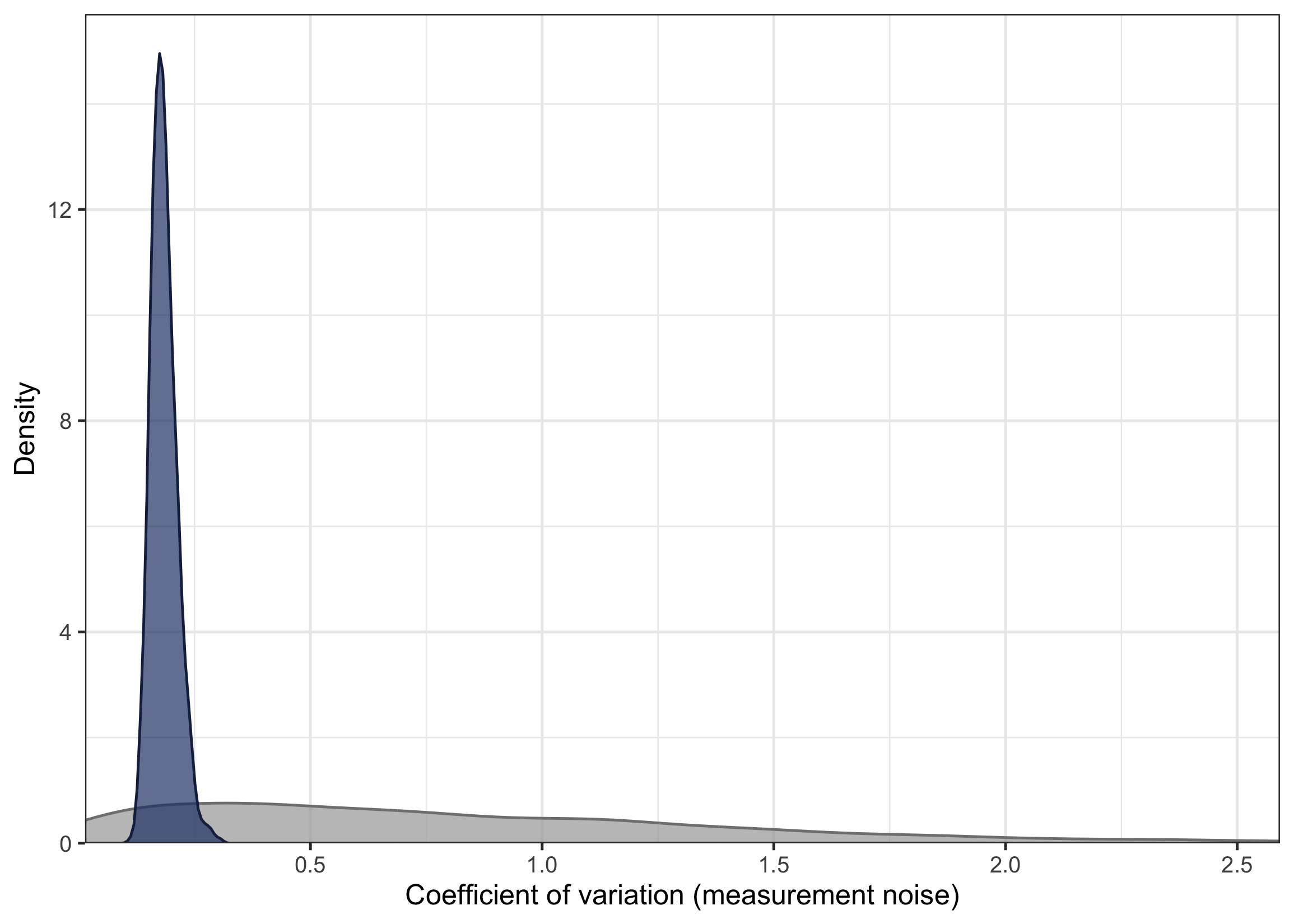 As we can see, the prior (in grey) and posterior (in blue) differ substantially, indicating that this parameter is well informed by the data.
As we can see, the prior (in grey) and posterior (in blue) differ substantially, indicating that this parameter is well informed by the data.
More details
We can further inspect our results object. It has the following attributes:
names(ww_result)
#> [1] "job" "stan_model" "checksums" "summary" "fitted"
#> [6] "diagnostics" "runtime"The job attribute stores all information about the job that was defined via EpiSewer. It contains the data used, alongside meta-information, and the settings for the sampler. By calling run(ww_result$job), the job can be run again.
names(ww_result$job)
#> [1] "job_name" "jobarray_size" "data" "model"
#> [5] "init" "fit_opts" "results_opts" "priors_text"
#> [9] "metainfo" "stan_digest" "overwrite"In particular, we can print a concise summary of the modeling details (the EpiSewer defaults in this case):
ww_result$job$model
#> measurements
#> |- concentrations_observe
#> |- noise_estimate
#> |- LOD_none
#>
#> sampling
#> |- outliers_estimate
#> |- sample_effects_none
#>
#> sewage
#> |- flows_observe
#> |- residence_dist_assume
#>
#> shedding
#> |- incubation_dist_assume
#> |- shedding_dist_assume (shedding_reference = symptom_onset)
#> |- load_per_case_calibrate
#> |- load_variation_estimate
#>
#> infections
#> |- generation_dist_assume
#> |- R_estimate_gp
#> |- seeding_estimate_rw
#> |- infection_noise_estimate (overdispersion = TRUE)➡️ Check out the model specification and detailed example vignettes to better understand the modeling details and customize the EpiSewer model.
The summary attribute stores summarized results for important parameters from the model.
names(ww_result$summary)
#> [1] "samples" "R"
#> [3] "R_diagnostics" "expected_infections"
#> [5] "infections" "growth_rate"
#> [7] "doubling_time" "days_growing"
#> [9] "expected_load" "expected_concentration"
#> [11] "concentration" "normalized_concentration"
#> [13] "outliers"For example, we can access the exact estimates for the reproduction number.
head(ww_result$summary$R, 5)
#> date mean median lower_0.95 lower_0.5 upper_0.5 upper_0.95
#> <Date> <num> <num> <num> <num> <num> <num>
#> 1: 2021-12-03 1.041682 1.038992 0.7659975 0.9446526 1.134036 1.350692
#> 2: 2021-12-04 1.042748 1.038827 0.7755440 0.9513116 1.131919 1.346471
#> 3: 2021-12-05 1.044001 1.039777 0.7874364 0.9543437 1.132151 1.335327
#> 4: 2021-12-06 1.045449 1.044896 0.7976320 0.9588722 1.129238 1.332912
#> 5: 2021-12-07 1.047096 1.047486 0.8045988 0.9617819 1.130224 1.326906
#> type seeding
#> <fctr> <lgcl>
#> 1: estimate TRUE
#> 2: estimate TRUE
#> 3: estimate TRUE
#> 4: estimate TRUE
#> 5: estimate TRUEThe fitted attribute provides access to all details of the fitted stan model (see cmdstanr for details). For example, we can use this to show sampler diagnostics for each chain:
ww_result$fitted$diagnostic_summary()
#> $num_divergent
#> [1] 0 0 0 0
#>
#> $num_max_treedepth
#> [1] 0 0 0 0
#>
#> $ebfmi
#> [1] 0.8409685 0.9463659 0.8608124 0.9331239Finally, the checksums attribute gives us several checksums that uniquely identify the job which was run. These can be used to check whether two job results used the same or different models, input data, fitting options, or inits. If all checksums are identical (and the seed is not NULL), then the results should also be identical.
ww_result$checksums
#> $model
#> [1] "9e1475ec1197cd29ff81d4f5a3f48928"
#>
#> $input
#> [1] "67660031772057ad86e6cdff143c8832"
#>
#> $fit_opts
#> [1] "bfdedc2ea8d89b577ad57b86ac83e706"
#>
#> $results_opts
#> [1] "e92f83d0ca5d22b3bb5849d62c5412ee"
#>
#> $init
#> [1] "4494611d40e53efdda644ca85a2fa9e9"Finding out more
EpiSewer offers comprehensive model customization and advanced plotting features. To find out more, please consult the package website.
Citing the package
If you are using EpiSewer in your work, please cite our paper:
@article{lisonRealTimeEstimation2026,
title = {Real-Time Estimation of Pathogen Transmission Dynamics from Wastewater},
author = {Lison, Adrian and McLeod, Rachel E. and Huisman, Jana S. and Munday, James D. and Ort, Christoph and Julian, Timothy R. and Stadler, Tanja},
year = {2026},
journal = {Nature Communications},
doi = {10.1038/s41467-026-75380-3}
}If you use the dPCR-specific model of EpiSewer (see noise_estimate_dPCR), please also this paper:
@article{lisonImprovingInference2026,
title={Improving Inference from Reported Concentrations in Environmental Surveillance by Modeling the Statistical Features of Digital PCR},
author={Lison, Adrian and Julian, Timothy R and Stadler, Tanja},
journal={ACS ES\&T Water},
year={2026},
doi = {10.1021/acsestwater.5c01051}
}Contributors
All contributions to this project are gratefully acknowledged using the allcontributors package following the all-contributors specification. Contributions of any kind are welcome!